What Is AI Context, Really? And Why It Matters More Than the Model
You paste a document into ChatGPT. You ask a question. The response misses something obvious, something you know was in the document.
What happened?
The answer almost always comes down to context, not intelligence. The model didn’t fail to understand. It failed to see.
Tokens Are Just Chunks of Text
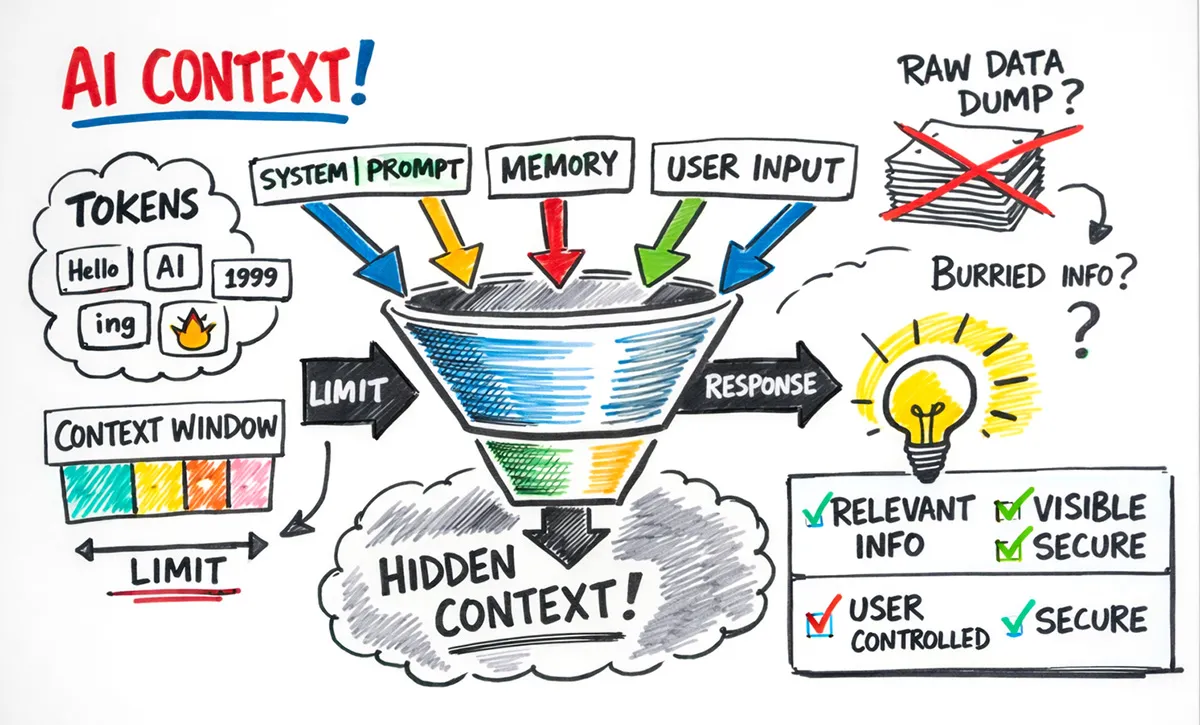
Large language models (LLMs) don’t process words. They process tokens, which are chunks of text the model has learned to recognize as meaningful units. A token might be a whole word, part of a word, or a single character depending on frequency and language.
In English, one token roughly equals four characters or about 0.75 words. A 1,500-page document might contain around 750,000 tokens.
This matters because every AI model has a hard limit on how many tokens it can process at once. That limit is called the context window, and it’s smaller than it appears.
The Advertised Numbers Are Misleading
Current advertised maximum context windows sound enormous:
- Gemini 2.5 Pro: 1 million tokens
- Claude Sonnet 4: 1 million tokens
- GPT-5: 400,000 tokens
- Claude Opus 4.5: 200,000 tokens
These numbers vary by plan, deployment mode, and provider configuration. But even at face value, they’re misleading because they represent the total window, not the space available to you.
Every conversation includes components that compete for the same limited space: system prompts, memory data, conversation history, your input, and the model’s response. Your actual usable space is whatever remains.
The Hidden Half of Every Conversation
Here’s where most users lose visibility, and where provider lock-in begins.
When you use ChatGPT, Claude, or Gemini, there’s a layer of context you don’t fully control. The system prompt alone can consume thousands of tokens. Then there’s memory.
ChatGPT now maintains two types: saved memories you explicitly create, and chat history, which are inferences the model builds from your past conversations. These get injected into every prompt, whether you realize it or not.
Developer Simon Willison documented how ChatGPT’s memory system had built an extensive profile on him: his location, programming preferences, interests, even personality inferences. All of this context was being added to every conversation. You can view some of it, but you can’t fully audit or restructure it. You’re optimizing partially blind.
Why Raw Context Doesn’t Equal Effective Context
Most people think about prompt length. They wonder whether their document is too long, whether they should split it up. These are reasonable questions, but they miss the larger issue.
Effective context isn’t about volume. It’s about how much relevant, well-structured information reaches the model at the moment of inference.
Memory systems that prioritize recency push out older context precisely when you need it. If you had a detailed conversation about a project six months ago, but recent conversations were unrelated, that detailed context gets summarized away or dropped entirely.
Unstructured context creates its own problems. A 100,000-token document dump might contain everything the model needs, but if the relevant information is buried on page 47, the model’s attention mechanism may not weight it appropriately.
Context architecture matters as much as context volume.
Where Your Tokens Actually Go
Every AI interaction follows a hidden formula:
Actual context = System prompt + Memory + Conversation history + User message + Response buffer
If your context window is 200,000 tokens and the system prompt consumes 8,000, memory adds 5,000, conversation history uses 50,000, and the model reserves 16,000 for its response, you have roughly 121,000 tokens for your actual input.
That’s 60% of the advertised capacity.
The problem compounds over long conversations. Every exchange adds to history. Memory accumulates inferences. By the time you’re deep into a working session, your effective context might be a fraction of what you started with.
This is why conversations degrade. It’s not that the model got stupider. It’s that your context got crowded.
Why Updates Make the Model Feel Dumber
There’s another way context fails that users rarely anticipate: model updates.
When providers release a new version, your memories and chat history typically persist. But the model interpreting that context is different. New system prompts, different fine-tuning, changed attention patterns. The same context that worked yesterday may not work today.
This is why a model can feel “dumber” after an update. Your memories didn’t disappear. The new model simply reads them differently, weights them differently, responds to them differently. Your carefully accumulated context doesn’t automatically translate to the new version.
You have no visibility into what changed. No way to adjust your context for the new model’s interpretation. The context you spent months building is now being read by a stranger.
The Bottleneck Isn’t Intelligence
The models are getting better. GPT-5 is smarter than GPT-4. Claude Opus 4.5 reasons more carefully than its predecessors. Gemini 3 handles longer documents with better recall.
But for most applied use cases, the bottleneck isn’t model intelligence. It’s context quality. Context control doesn’t replace better models, but it determines how much of a model’s capability you actually get.
A mediocre model with excellent context often outperforms a frontier model with poor context. If you’ve ever had ChatGPT nail a task because you carefully structured your prompt, while watching it fail on the same task when you asked casually, you’ve experienced this firsthand.
LLM providers are incentivized to improve their models. Their incentives around context visibility are more conflicted: transparency builds trust, but lock-in builds retention. The result is incremental progress on user control while the context that shapes your results remains largely provider-managed.
The models will keep improving. Context windows will keep expanding. But unless users gain visibility and control over what fills those windows, the improvements won’t translate into proportionally better results.
What’s missing is a layer that treats context as a first-class, user-controlled system.
What would change about how you use AI if you could see and control every piece of context that reaches the model?